blog
Markov: A Lightweight, YAML-First Workflow Engine for Chaining AI Agent Jobs on Kubernetes
If you have spent any time trying to chain AI agent jobs on Kubernetes – run an LLM-powered code review, evaluate the output against quality criteria, conditionally trigger a security scan, loop back if the results fall short – you have probably discovered an uncomfortable truth: the existing tool landscape forces you to choose.
You can have heavyweight durability (Temporal), but you will deploy a server cluster, a database, and write imperative code in Go or Python. You can have Kubernetes-native execution (Argo Workflows), but you will install Custom Resource Definitions, manage an operator, and accept that your workflows cannot loop – DAGs are acyclic by definition. You can have familiar YAML semantics (Ansible), but your execution model is SSH-based, stateless, and unaware of Kubernetes Jobs. You can have purpose-built agent orchestration (LangGraph), but you will write Python, run everything in-process, and manage your own infrastructure.
No single tool gives you all four: Ansible-style YAML definitions, rule-engine gating for conditional logic, recursive state-machine workflows that can loop until quality criteria are met, and lightweight Kubernetes-native execution without CRDs.
That gap is why markov exists.
The Research That Shaped the Design
Markov did not emerge from a whiteboard session. It grew out of a multi-month applied research program that studied workflow orchestration for AI agent jobs from four angles: architecture patterns, competitive landscape, production failure modes, and prototype validation.
The research began with a practical question from a platform engineering team: how should we chain Claude agent jobs on Kubernetes with gating criteria between steps? The team needed workflows that could run an agent, evaluate its output against business rules, and decide – deterministically, not probabilistically – whether to proceed, retry, or escalate.
We surveyed 16 tools across five categories. We built prototypes. We studied how production teams at scale handle agent orchestration. Three findings shaped everything that followed.
Finding one: the deterministic harness wins. The 2026 industry consensus, validated by organizations running agent workflows at production scale, is unambiguous. Agents should not orchestrate themselves. Early experiments with self-orchestrating agents – where the LLM decided what phase it was in and what to run next – produced circular dependencies, skipped steps, and analysis loops on larger codebases. The pattern that works is “Agent equals Model plus Harness”: a deterministic external system controls workflow progression, and agents execute bounded work within individual steps. The QuantumBlack finding crystallized this: “Agents don’t decide what phase they’re in – the workflow engine does.”
Finding two: rule engines and workflow engines serve different purposes. A workflow engine answers “given the process, what is the next step?” A rule engine answers “given these conditions, what should happen?” Trying to make one system do both produces either brittle conditional chains (nested when clauses that become unreadable at depth) or over-engineered workflow logic that embeds business rules in control flow. The architectural recommendation was clear: separate the concerns. Use YAML workflows for sequencing. Use a rule engine for conditional evaluation. Connect them through gate steps.
Finding three: a genuine whitespace exists. After mapping every tool’s capabilities against the requirements, we documented a gap. No existing system combined Ansible-style YAML semantics, production rule-engine gating, recursive workflow execution, and Kubernetes-native job orchestration. Teams were composing three or four separate tools to approximate this combination. The gap was not a marketing claim – it was a measured absence across 16 surveyed options.
Markov is the implementation that fills that gap.
What Markov Does
Markov is a single Go binary that executes YAML-defined workflows. It runs steps sequentially within workflows, manages concurrency explicitly through fan-out blocks, evaluates gate conditions through a forward-chaining rule engine, and persists checkpoint state to SQLite for crash recovery and resume.
The architecture is deliberately minimal. No server process runs continuously. No operator watches for custom resources. No database cluster requires provisioning. You write a YAML file, run a command, and markov creates Kubernetes batch/v1 Jobs for each step. When a step completes, its output becomes available to subsequent steps as template variables. If the process fails, you resume from the last successful checkpoint.
Eight Primitive Step Types
Markov ships with eight built-in step types, each serving a distinct role in agent workflow orchestration:
k8s_job creates and monitors a Kubernetes batch/v1 Job. You specify the container image, command, environment variables, volume mounts, resource limits, and namespace. Markov handles Job creation, log capture, and completion detection. The RBAC surface is three verbs on three resources – create and get on Jobs, list and get on Pods, and get on Pod logs. Compare this to Argo Workflows, which requires ten or more verbs across ten or more resource types including CRD permissions.
llm_invoke signals that markov has first-class awareness of LLM agent invocation as a workflow primitive, not merely a generic container execution. This matters because agent-specific orchestration features – context propagation, output evaluation, retry with modified prompts – require the engine to understand what it is orchestrating.
gate evaluates rules defined in YAML through the Grule rule engine. Rules use forward chaining with salience-based priority resolution. When multiple rules fire, the highest-salience action wins. Gate actions modify workflow execution: continue, skip, or pause. Fired rules can inject new facts into the workflow context, influencing subsequent steps.
set_fact mutates the workflow context, making computed values available to downstream steps through Jinja2-compatible template rendering (via pongo2). This is the direct analog of Ansible’s set_fact module.
for_each fans out execution across a collection with configurable concurrency. The forks parameter, defaulting to 5, controls how many iterations run simultaneously, implemented as goroutines with a buffered channel semaphore. Each iteration receives an isolated context copy, preventing data races.
assert validates conditions and halts execution with a descriptive failure message if they are not met – the workflow equivalent of a test assertion.
load_artifact ingests YAML, Markdown, or tabular data files into the workflow context for downstream processing.
http_request makes HTTP calls, enabling integration with external APIs, webhooks, and notification systems.
Beyond these primitives, markov supports user-defined step types – reusable templates that compose a base type with default configuration:
step_types:
code_review_agent:
type: k8s_job
defaults:
image: my-registry/claude-runner:latest
namespace: agents
params:
timeout: 3600
Steps using code_review_agent inherit the container image, namespace, and timeout, then overlay step-specific parameters. Teams can define libraries of skill types – security_scan, documentation_gen, test_runner – that encapsulate operational defaults while remaining customizable per invocation.
The Gate System: Where Markov Diverges
Rule-engine gating is markov’s most architecturally distinctive feature, and the single strongest differentiator against every competitor in this comparison. Zero tools in the surveyed landscape – Temporal, Argo, Tekton, Kestra, Hatchet, LangGraph, Jenkins – integrate a production rule engine for workflow gating.
The implementation works in three layers. YAML rule definitions are translated to GRL (Grule Rule Language) at evaluation time. A typed FactStore wraps the runtime context, exposing accessors – GetStr(), GetNum(), IsTrue(), IsNil() – that enforce type safety without the fragility of stringly-typed fact systems. The Grule engine evaluates rules with forward chaining, and salience determines which action takes precedence when multiple rules fire.
A gate step in practice:
- name: quality_check
type: gate
rules:
- name: passing_quality
when: "score >= 85 and coverage > 0.80"
then:
set_fact:
quality_action: continue
salience: 10
- name: marginal_quality
when: "score >= 70 and score < 85"
then:
set_fact:
quality_action: retry_with_feedback
salience: 5
- name: failing_quality
when: "score < 70"
then:
set_fact:
quality_action: escalate
salience: 1
This is not a nested if/elif/else chain. It is a forward-chaining rule evaluation with explicit priority ordering. Rules can fire based on combinations of facts accumulated across prior steps. The salience mechanism provides deterministic conflict resolution. And because fired rules can inject new facts, gate evaluations propagate state that downstream steps consume – creating inference chains without imperative control flow.
Recursive Workflows: The Feature No DAG Engine Can Express
Argo Workflows enforces acyclic directed graphs. Tekton pipelines are linear. These are not implementation oversights – they are architectural constraints. A DAG, by definition, cannot cycle.
Markov’s workflow model is a recursive state machine. Workflows can invoke themselves:
workflows:
- name: iterative_refinement
steps:
- name: run_agent
type: k8s_job
params: { ... }
register: agent_result
- name: evaluate_quality
type: gate
rules: [quality_check]
- name: recurse_if_needed
type: workflow
workflow: iterative_refinement
when: "{{ quality_action == 'continue' }}"
This enables patterns that are natural for AI agent workflows but impossible in DAG-based engines: iterative refinement loops (run agent, evaluate, retry if insufficient), polling workflows (check external state, act or wait, re-check), and multi-phase pipelines where each phase decides whether to proceed or loop back.
Each recursive invocation creates a child run with parent tracking, persisted in the state store. The full execution tree is reconstructable. Termination is controlled by gate rules, not by the engine – the workflow author defines when recursion stops.
Checkpoint and Resume
Every step completion is persisted to SQLite with ACID guarantees. The state store tracks two entities: runs, with workflow file, entrypoint, status, variables, parent run ID, and timing; and steps, with status, output, artifacts, errors, and timing. The composite primary on steps – run ID, workflow name, step name – enables precise reconstruction.
On resume, the engine loads the prior run, replays completed step outputs to reconstruct the runtime context, skips completed steps, and restarts execution from the first incomplete or failed step. The upsert pattern, INSERT...ON CONFLICT DO UPDATE, provides idempotent re-execution.
The choice of pure-Go SQLite, via modernc.org/sqlite with no CGO dependency, is a pragmatic engineering decision. It eliminates cross-compilation headaches, enables true single-binary distribution, and provides sufficient durability for single-instance deployment. The state.Store interface is defined abstractly – swapping in PostgreSQL for multi-instance deployment is architecturally feasible, though not yet implemented.
What Markovd Adds
Markovd is the companion dashboard for markov. It provides operational visibility into workflow execution without coupling to the CLI’s execution model.
The architecture is cleanly decoupled. Markovd launches markov as a subprocess with callback URLs configured. As markov executes, it POSTs lifecycle events – 12 event types covering run, step, gate, and sub-run state transitions – back to the markovd API. Markovd persists events to PostgreSQL and serves them to a React frontend. The markov CLI remains independently usable. The dashboard is additive, not required.
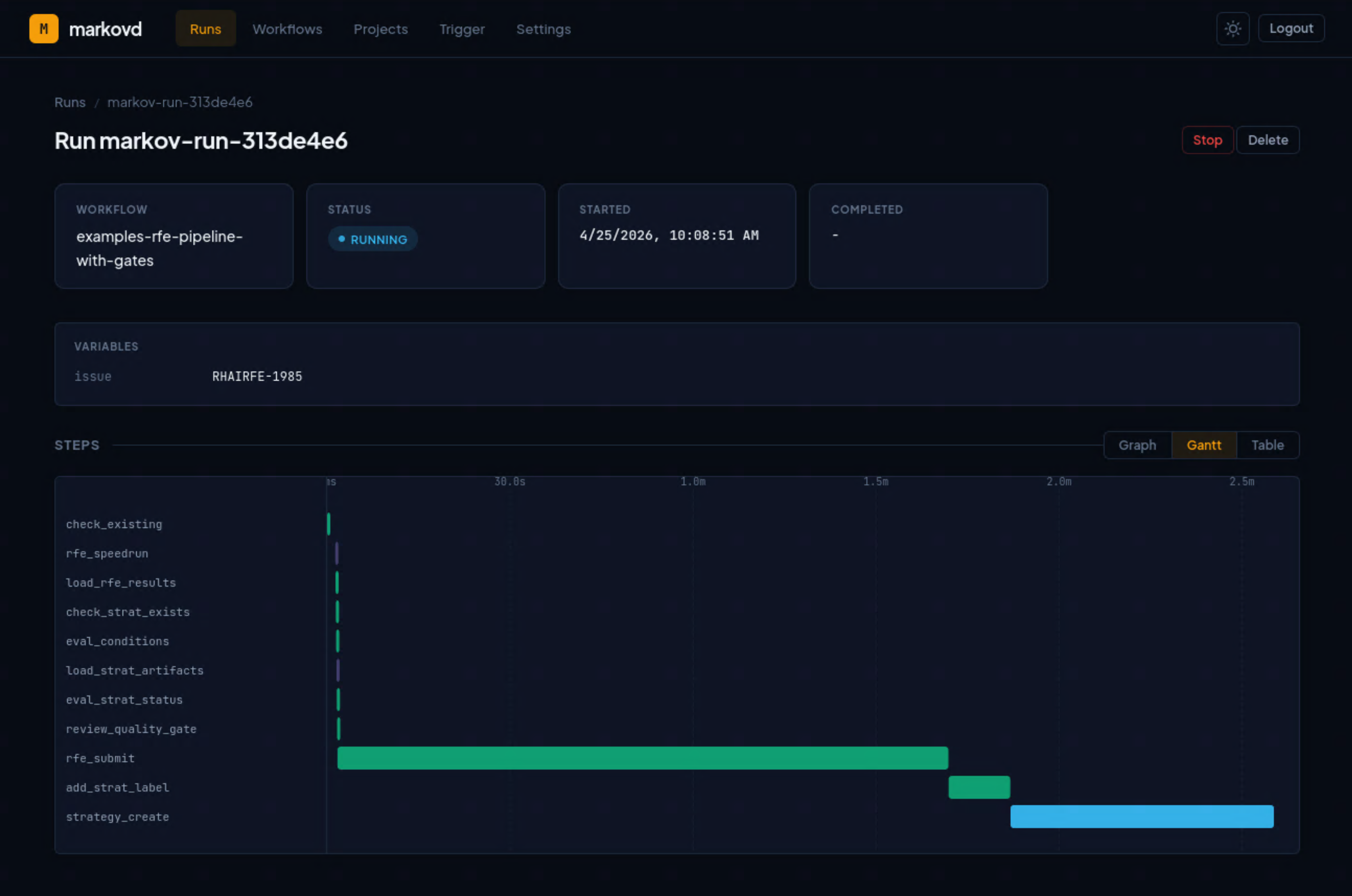
The frontend provides three visualization modes, each serving a different monitoring need:
DAG visualization renders the workflow structure as an interactive directed graph using React Flow. Nodes are color-coded by execution status. This view answers “what is the shape of my workflow and where is execution currently?”
Gantt timeline shows step durations and concurrency over time. This view answers “how long did each step take, and what ran in parallel?”
Step table provides a sortable, filterable list of all steps with fork context, status badges, and error details. This view answers “which specific step failed and why?”
The technology stack is conventional and production-appropriate: Go with Chi router for the API server, PostgreSQL 16 for persistence, bcrypt plus JWT for authentication, React with TypeScript and Vite for the frontend, and go-git for pulling workflow definitions directly from repositories – enabling GitOps-style workflow management.
How Markov Compares
The competitive landscape for workflow orchestration is crowded but segmented. Markov’s position is narrow and specific: it targets platform engineers who need declarative, YAML-first agent job orchestration on Kubernetes with conditional gating logic. Understanding where markov fits requires comparing it against the tools teams actually consider.
Against Argo Workflows – the incumbent Kubernetes-native workflow engine – markov’s advantages are structural. No CRDs means simpler installation and a dramatically smaller RBAC surface, three verbs on three resources versus ten or more on ten or more. Recursive workflows address use cases Argo cannot express architecturally. Rule-engine gating provides richer conditional logic than Argo’s when expressions. The trade-off is maturity: Argo is CNCF Graduated with 16,600 GitHub stars, rich artifact management, the Hera Python SDK, and years of production hardening at organizations including Intuit, BlackRock, and NVIDIA.
Against Temporal – the strongest competitor on the durability axis – markov trades fault-tolerance depth for operational simplicity. Temporal’s event-sourcing model provides stronger replay guarantees. Its polyglot SDK support, enterprise cloud offering, and production adoption at Stripe, Netflix, and Coinbase represent a level of maturity markov does not claim. But Temporal requires a server cluster with a database backend, imposes a 2-4 week learning curve for its deterministic function model, and is code-first. For teams that want YAML-declarative agent job chains on Kubernetes, Temporal is architecturally overqualified.
Against Ansible – markov’s closest YAML-semantic ancestor – the distinction is execution model. Ansible automates infrastructure via SSH. Markov orchestrates Kubernetes Jobs with checkpoint/resume and rule-engine gating. The YAML semantics are deliberately similar, when, set_fact, for_each, Jinja2 templates, to lower the learning curve for the largest automation user base in the industry. But the underlying execution primitives are fundamentally different.
Against LangGraph – the dominant AI agent framework, with 97,000 or more stars in the LangChain ecosystem – markov and LangGraph are complementary, not competing. LangGraph operates at the agent-logic layer: what the agent does, how it reasons, how it manages memory. Markov operates at the infrastructure-orchestration layer: when jobs are scheduled, where they execute, whether gate conditions are met, and how state is checkpointed. A production system can use both – markov orchestrating Kubernetes Jobs that internally run LangGraph agents.
Against Kestra, Hatchet, and Tekton, the pattern holds. Kestra is the enterprise platform play, 30,000 stars, $25M Series A, 1,200 or more plugins, targeting breadth. Hatchet is the closest AI-native competitor but is code-first, not YAML-declarative. Tekton is a CI/CD tool optimized for build pipelines, lacking the gating and recursion capabilities agent workflows demand.
The consistent finding across all nine comparisons: rule-engine gating is the single strongest differentiator. No tool in this set integrates a production rule engine for workflow gate evaluation.
Research Origins: From Analysis to Implementation
What makes this announcement different from a typical open-source launch post is the documented lineage between research findings and implementation decisions. Fourteen specific design choices in markov trace to recommendations, gap analyses, or prototype validations from our research program. The most significant threads:
The Grule adoption traces directly to an annotated bibliography of rule engine patterns that profiled Grule as the lightweight Go alternative to Drools and recommended evaluating it for workflow gating. Markov adopted Grule as its core decision engine – the exact recommendation, implemented in the exact language ecosystem.
The rule engine and workflow engine separation – YAML workflows for sequencing, Grule for conditional evaluation, gate steps as the connection point – was an explicit architectural recommendation: “Don’t try to make one do both.” Markov implements this separation precisely as specified.
The four-way intersection that markov claims as its market position was first articulated as an unserved whitespace in our gap analysis. The finding that no existing tool combined Ansible YAML semantics, rule-engine gating, recursive state machines, and Kubernetes-native orchestration predates and directly motivates the implementation.
The deterministic harness philosophy – agents execute within steps, the workflow engine controls progression – was the central conclusion of empirical research into agent orchestration strategies. The QuantumBlack corroboration, “agents don’t decide what phase they’re in,” became markov’s foundational design principle.
The visualization architecture in markovd, React Flow DAG, Gantt timeline, and step table, implements the three-view pattern identified in our follow-up research on workflow visualization UX, using the exact library our technical analysis recommended.
The no-CRD Kubernetes integration reflects findings from both our bibliography of Kubernetes workflow tools and our RBAC analysis, which identified CRD installation and elevated permissions as adoption barriers in shared cluster environments.
Five areas from our research remain unimplemented – full Truth Maintenance System propagation, human-in-the-loop approval gates, complexity-based zone classification for task routing, formal queueing models for throughput planning, and supply chain security for workflow definitions. These represent the next horizon of development, not gaps in the current design thesis.
When to Use Markov
Markov is not the right tool for every workflow orchestration problem. The decision depends on what you need:
Choose markov when your workflows chain AI agent jobs on Kubernetes with conditional gating criteria. When you want Ansible-familiar YAML without Ansible’s SSH execution model. When your workflows need to loop – iterative refinement, polling, multi-phase evaluation – and DAG-only engines cannot express the pattern. When you want the lightest possible Kubernetes integration footprint: no CRDs, no operators, no controller deployments. When rule-engine evaluation of gate conditions is more expressive than nested when clauses.
Choose Argo Workflows when your workflows are acyclic, your team already has Argo infrastructure, and you need rich artifact management with S3 or GCS integration. Argo’s maturity and ecosystem depth are unmatched in the Kubernetes-native workflow space.
Choose Temporal when you need battle-tested durable execution at massive scale, polyglot SDK support, and event-sourced replay guarantees. Temporal’s infrastructure weight is justified when your reliability requirements demand it.
Choose LangGraph when your challenge is agent-level orchestration – reasoning, memory, tool use, multi-agent coordination – rather than infrastructure-level job scheduling. LangGraph and markov can work together: markov schedules and gates the jobs, LangGraph runs inside them.
Choose Kestra or Hatchet when you need a managed platform with enterprise features, RBAC, audit trails, multi-tenancy, cloud hosting, and are willing to trade markov’s minimalism for operational maturity.
Getting Started
Markov is available on GitHub:
- markov (workflow engine): github.com/jctanner/markov
- markovd (dashboard): github.com/jctanner/markovd
Markov is a Go binary. Build it, point it at a YAML workflow file, and run. If you have kubectl configured, markov will create Kubernetes Jobs in your current context. If you do not, local step types, shell_exec, http_request, set_fact, gate, and assert, work without a cluster.
The project is early-stage. The architecture is sound – our technical review found 10 of 15 research-recommended patterns strongly aligned, with gaps concentrated in security hardening rather than structural design. Test coverage, structured logging, and production observability instrumentation are areas for contribution.
What markov offers today is a thesis validated by research: the four-way intersection of Ansible YAML, rule-engine gating, recursive state machines, and Kubernetes-native execution is a real and unoccupied position in the workflow orchestration landscape. If that intersection describes the problem you are solving, markov is built for you.